Dimension Reduction
핵심 키워드
- Scree Plot
- Supervised / Unsupervised Learning
- K-means clustering
Scree plot
각 PC의 Variation에 대한 그래프
- x 축 은 PC, y축은 pca.explained_variance_
Supervised (지도학습)
- 지도학습 : 트레이닝 데이터에 라벨(답)이 있을 때
- 분류 (Classification) 분류 알고리즘은 주어진 데이터의 카테고리 혹은 클래스 예측을 위해 사용
- 회귀 (Prediction) 회귀 알고리즘은 continuous 한 데이터를 바탕으로 결과를 예측 하기 위해 사용
Unsupervised Learning (비지도학습)
- 비지도학습 : 트레이닝 데이터에 라벨(답)이 없을 때
- 차원 축소 (Dimensionality Reduction) 높은 차원을 갖는 데이터셋을 사용하여 feature selection / extraction 등을 통해 차원을 줄이는 방법
- 연관 규칙 학습 (Association Rule Learning) 데이터셋의 feature들의 관계를 발견하는 방법 (feature-output 이 아닌 feature-feature)
- 클러스터링 (Clustering) 데이터의 연관된 feature를 바탕으로 유사한 그룹을 생성
Reinforcement Learning (강화 학습)
- 강화 학습 : 기계가 좋은 행동에 대해서는 보상, 그렇지 않은 행동에는 처벌이라는 피드백을 통해서 행동에 대해 학습해 나가는 형태
Clustering
- 목적 : 데이터들이 얼마나, 어떻게 유사한가 / 주어진 데이터 셋을 요약, 정리하는데 효율적인 방법
K-means Clustering
- 과정
1) k 개의 랜덤한 데이터를 cluster의 중심점으로 설정
2) 해당 cluster에 근접해 있는 데이터를 cluster로 할당
3) 변경된 cluster에 대해서 중심점을 새로 계산
- K-means with Scikit-learn
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3)
kmeans.fit(x)
labels = kmeans.labels_
- Elbow Method : 특정 K 이후 cost가 거의 변하지 않는 elbow point 가 있다면 그 K를 선택하는 것이 합리적
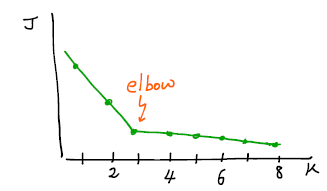
sum_of_squared_distances = []
K = range(1, 15)
for k in K:
km = KMeans(n_clusters = k)
km = km.fit(points)
sum_of_squared_distances.append(km.inertia_)
plt.plot(K, sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()
- 참고 블로그
[31편] k-means 클러스터링 - 최적 클러스터 개수 찾기
데이터 분포를 그래프로 표현하면 데이터가 몇개의 그룹으로 분류될 수 있는지 눈으로 확인할 수 있습니다....
blog.naver.com
Data Scaling
- Data Scaling : 서로 다른 변수의 값에 대한 범위를 일정한 수준으로 맞추는 작업
- StandardScaler : 각 feature의 평균을 0, 분산을 1로 변경, 모든 특성들이 같은 스케일을 갖게 됨
- RobustScaler : 모든 특성들이 같은 크기를 갖는다는 점에서 StandardScaler와 비슷하지만, 평균과 분산 대신 median과 quartile을 사용, RobustScaler는 이상치에 영향을 받지 않음
- MinMaxScaler : 모든 feature가 0과 1사이에 위치 시킴, 데이터가 2차원 셋일 경우, 모든 데이터는 x축의 0과 1 사이에, y축의 0과 1사이에 위치
- Normalizer : StandardScaler, RobustScaler, MinMaxScaler가 각 columns의 통계치를 이용한다면 Normalizer는 row마다 각각 정규화함.
* 참고 블로그 : jaaamj.tistory.com/20
'[CodesSates] AI 부트캠프' 카테고리의 다른 글
| Multiple Regression (0) | 2021.04.06 |
|---|---|
| Simple Regression (0) | 2021.04.05 |
| Dimension Reduction (0) | 2021.03.22 |
| Linear Algebra + (0) | 2021.03.21 |
| Vector / Matrix (0) | 2021.03.21 |