Hypothesis Test2
T-Test 조건
- 독립성 : 두 그룹이 연결되어 이쓴 (paired) 쌍인지 (cat or cat vs cat or dong)
- 등분산성 : 두 그룹이 어느정도 유사한 수준의 분산 값을 가지는지/ normaltest(data)
- 정규성 : 데이터가 정규성을 나타내는지
Non parametric methods
- Categorical 데이터를 위한 모델링
- 극단적인 Outlier가 있는 경우 유효한 방식
- 대표적으로 Chisquare, Kruskal-wallis test
키, 몸무게와 같은 연속형 자료(수량화 할 수 있는 데이터)를 분석할 때에는 T-test와 ANOVA 분석 방법이 사용된다.
반면에, 성별, 혈액형 등 범주형 자료(수량화 할 수 없는 데이터)를 분석할 때는 카이제곱검정법이 사용된다.
One sample chi-squared
- 주어진 데이터가 특정 예상되는 분포와 동일한 분포를 나타내는지에 대한 검정
주사위를 총 120번 던진다고 가정
fair 주사위 라면 공정하게 20번씩 나온다고 예상할 수 있지만 실제는 그렇지 않다
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 예상 | 20 | 20 | 20 | 20 | 20 | 20 |
| 실제 | 17 | 23 | 19 | 21 | 13 | 27 |
| 실제 | 3 | 27 | 14 | 26 | 26 | 24 |
H0 : 분포가 동일할 것이다.(1~6에서 각각의 범주가 일어날 확률이 동일할 것)
H1 : 분포가 동일하지 않다.
obs = 관측 데이터
exp = 기대 값
from scipy.stats import chisquare
import numpy as np
obs1 = np.array([19, 23, 20, 18, 22, 21])
chisquare(obs1, axis=None)
# Power_divergenceResult(statistic=0.8536585365853658, pvalue=0.9734853457112421)
# pvalue가 약 0.97로 충분히 큰 값 => 귀무가설 채택. 분포가 동일할 것이다.
obs2 = np.array([2, 33, 6, 23, 8, 26])
chisquare(obs2, axis=None)
# Power_divergenceResult(statistic=48.816326530612244, pvalue=2.4195922231210123e-09)
# pvalue가 0.0000..으로 굉장히 작다. => 귀무가설 기각. 대립가설 채택. 분포가 동일하지 않을 것이다.
Two sample chi-square
-두 개의 변수(명목척도) 사이에 연관성이 있는지 확인하기 위한 검정
바이러스 감염과 혈앵형의 연관성에 대한 분석을 한다고 가정
H0 : 바이러스와 혈액형 사이에는 연관성이 없다.
H1 : 바이러스와 혈액형 사이에는 연광성이 있다.
from scipy.stats import chi2_contingency
obs = pd.crosstab(df['virus'], df['bloodtype'])
print(chi2_contingency(obs, correction = False))
One-tailed VS Two-tailed
- One-tailed
H0 : 모집단의 평균이 A와 같다
H0 : 모집단의 평균이 A보다 작다 or 크다
유의수준이 0.05 라면, One-tailed는 한 방향으로 유의수준을 모두 할당
만약 H1을 '모집단의 평균이 A보다 크다' 라고 가정하면 오른쪽에만 0.5 위치
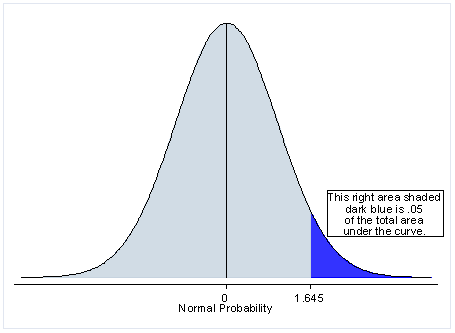
- Two-tailed
H0 : 모집단의 평균이 A와 같다.
H1 : 모집단의 평균이 A와 다르다.
유의수준이 0.05라면. 반으로 값을 나누어 양 쪽에 0.025

'[CodesSates] AI 부트캠프' 카테고리의 다른 글
| Bayesian (0) | 2021.03.19 |
|---|---|
| Confidence Interval (0) | 2021.03.16 |
| Hypothesis Test (0) | 2021.03.14 |
| Data Visualize (0) | 2021.03.09 |
| Data Manipulation (0) | 2021.03.09 |