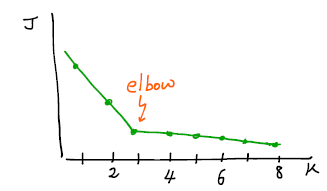
Ridge Regression Pandas-Profiling - 데이터 타입, 결측값, 중복 등 다양한 정보 확인 가능 매우 유용 - df.profile_report() wikidocs.net/47193 위키독스 온라인 책을 제작 공유하는 플랫폼 서비스 wikidocs.net One Hot Encoding - 범주형 변수(Categorical)는 순서가 없는 명목형(nominal)과 순서가 있는 순서형(ordinal)로 나뉨. - pd.get_dummies 활용 # prefix 컬럼에 지정한 글자로 시작하도록 # drop_first 불필요한 요소 제거 pd.get_dummies(df, prefix ['text'], drop_first=True) - category_encoders 활용 ## import ..